
Conversational AI chatbot using Rasa NLU & Rasa Core: How Dialogue Handling with Rasa Core can use LSTM by using Supervised and Reinforcement Learning Algorithm
In this Article, I will explain in conversational AI chatbot how we can apply dialogue handling with rasa core by using LSTM based Supervised learning and Reinforcement learning. Basically, The Rasa core and Rasa NLU are open source python libraries for creating conversational software. Their purpose is to make machine-learning based dialogue management and language understanding accessible to non-specialist software developers. The main component of the model is a recurrent neural network (an LSTM), which maps from raw dialog history directly to a distribution over system actions. The LSTM automatically infers a representation of dialog history, which relieves the system developer of much of the manual feature engineering of dialog state. In addition, the developer can provide software that expresses business rules and provides access to programmatic APIs, enabling the LSTM to take actions in the real world on behalf of the user. The LSTM can be optimized using supervised learning (SL), where a domain expert provides example dialogs which the LSTM should imitate; or using reinforcement learning (RL), where the system improves by interacting directly with end users.
The following image will show that how conversational software is associated with machine learning:

Steps to create conversational AI chatbot using Rasa NLU & Rasa Core
- Introduction
- Natural Language Understanding (NLU)
- Natural Language Generation (NLG)
- RNN or LSTM
- Rasa NLU
- Rasa Core
- Supervised Learning
- Reinforcement Learning
- Entity Extraction
- Intent Classification
- Role of NLU and NLG in Conversational AI chatbot
- How Create a Sample Dataset for Rasa NLU chatbot
- Dialog Handling with Rasa Core
- How Rasa NLG works
- How LSTM can handle dialog system using Supervised and Reinforcement Learning Algorithm
- Script to create conversational AI chatbot by using Rasa NLU and Rasa core with integration with Flask
Introduction
Now a days the Conversational systems are becoming pervasive as a basis for human computer interaction as we seek more natural ways to integrate automation into everyday life. Well-known examples of conversational AI include Apple’s Siri, Amazon’s Alexa and Microsoft’s Cortana but conversational systems are becoming widespread with platforms like Facebook Messenger opening up to chatbot developers. Common tasks for conversational systems include to buy movie tickets , booking flights, Book doctor’s appointments and customer support task.
Rasa takes inspiration from a number of sources for building a conversational AI chatbot. In this, Rasa’s API uses ideas from scikit-learn and Keras, and indeed both of these libraries are components of a Rasa application and the text classification is loosely based on the fastText approach. Sentences are represented by pooling word vectors for each constituent token. Using pre-trained word embedding such as GloVe , the trained intent classifiers are remarkably robust to variations in phrasing when trained with just a few examples for each intent.
Natural language understanding (NLU)
Rasa NLU is a kind of natural language understanding module. It comprises loosely coupled modules combining a number of natural language processing and machine learning libraries in a consistent API. There are some predefined pipelines like spacy_sklearn, tensorflow_embedding, mitie, mitie_sklearn with sensible defaults which work well for most use cases. For example, the recommended pipeline, spacy_sklearn, processes text with the following components. First, the text is tokenised and parts of speech (POS) annotated using the spaCy NLP library. Then the spaCy featuriser looks up a GloVe vector for each token and pools these to create a representation of the whole sentence. Then the scikit-learn classifier trains an estimator for the dataset, by default a mutliclass support vector classifier trained with five-fold cross-validation. The ner_crf component then trains a conditional random field to recognize the entities in the training data, using the tokens and POS tags as base features. Since each of these components implements the same API, it is easy to swap the GloVe vectors for custom, domain-specific word embeddings, or to use a different machine learning library to train the classifier. There are further components for handling out-of-vocabulary words and many customization options for more advanced users.
Example:
spacy_sklearn use spacy as a template:
language: "en"
pipeline: "spacy_sklearn"we can use the component and configure it separately as below,language: "en"pipeline:
- name: "nlp_spacy"
- name: "tokenizer_spacy"
- name: "intent_entity_featurizer_regex"
- name: "intent_featurizer_spacy"
- name: "ner_crf"
- name: "ner_synonyms"
- name: "intent_classifier_sklearn"
tensorflow_embedding can use it as a template as below,
language: "en"
pipeline: "tensorflow_embedding"we can configure tensorflow_embedding as below, language: "en"pipeline:
- name: "tokenizer_whitespace"
- name: "ner_crf"
- name: "ner_synonyms"
- name: "intent_featurizer_count_vectors"
- name: "intent_classifier_tensorflow_embedding"
Note: tensorflow_embedding pipeline makes it possible to train models which can assign two or more intents to a single input message. Take an random example for taxi booking, when a user says “Yes, make a booking. Can you also book me a taxi from the airport to the hotel?” there are two intentions — confirmation that the booking should be made and an additional request to book a taxi. We can model such inputs by assigning them multi-intents, so in the above example the intent would be confirm+book_taxi.
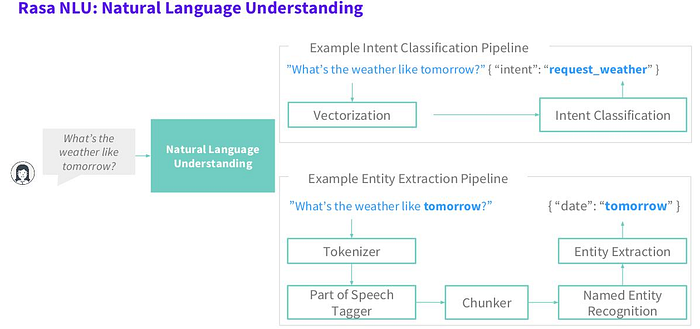
The following image show how NLU works to classify intent of user’s input and extract the entity using pipeline,
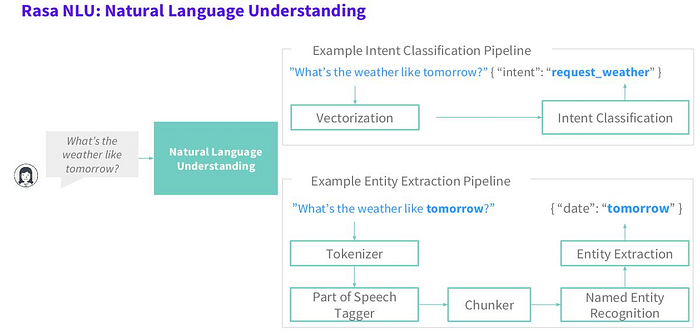
Natural Language Generation (NLG)
Natural Language Generation (NLG) is a subdivision of Artificial Intelligence (AI) that aims to reduce communicative gaps between machines and humans. The technology, typically accepts input in non-linguistic format and turn it into human understandable formats like reports, documents, text messages etc. Example:
Numerical Weather Reports into Text (Automation)
Most of the weather forecasting systems use Natural Language Processing to interpret the numerical values that are received as an input from supercomputers. Just take example of how fog is reported. A numerical prediction of wind speed, intensity of precipitation, and other meteorological phenomena are recorded. For converting this data into a language (text, audio, print, or any other form) that humans understand, Natural Language Generation can be used. The system will continue to receive the values and NLG interprets them into human understandable format.
LSTM
LSTM networks have some internal contextual state cells that act as long-term or short-term memory cells. The output of the LSTM network is modulated by the state of these cells. This is a very important property when we need the prediction of the neural network to depend on the historical context of inputs, rather than only on the very last input. LSTMs solve the gradient problem by introducing a few more gates that control access to the cell state.
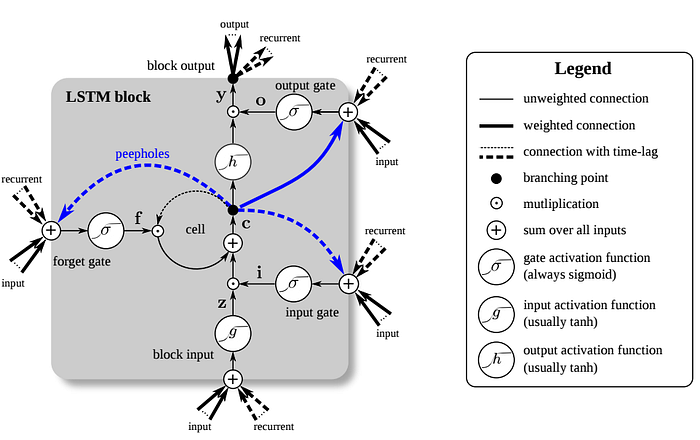
Rasa NLU
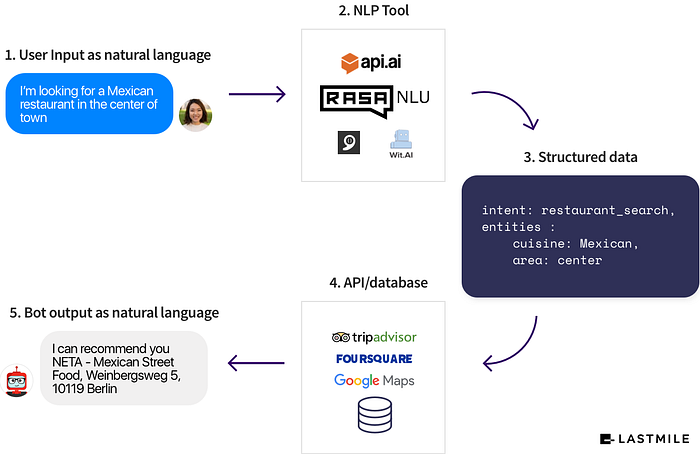
Rasa NLU is an open-source natural language processing tool for intent classification and entity extraction in Conversational AI chatbots. For example, taking a sentence like,
sentence="I am looking for a Mexican restaurant in the center of town"
After passing the command like,
python -m rasa_nlu.train -c sample_configs/config_spacy.jsonwe will get the structured data like
{
"intent": "search_restaurant",
"entities": {
"cuisine" : "Mexican",
"location" : "center"
}
}Rasa NLU runs wherever you want, so you don’t have to make an extra network request for every message that comes in.
Rasa Core :Dialogue Handling
Rasa Core predicts which action to take from a predefined list. An action can be a simple utterance, i.e. sending a message to the user, or it can be an arbitrary function to execute. When an action is executed, it is passed a tracker instance, and so can make use of any relevant information collected over the history of the dialogue: slots, previous utterances, and the results of previous actions. Actions cannot directly mutate the tracker, but when executed may return a list of events. The tracker consumes these events to update its state. There are a number of different event types, such as SlotSet, AllSlotsReset, Restarted, etc.
The following image shows that how the how the Rasa Core and Rasa NLU work together,
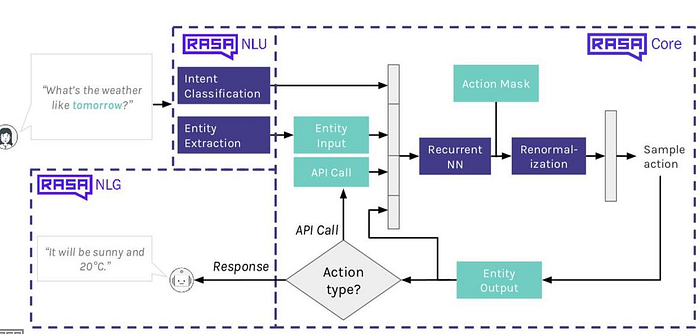
Supervised Learning
Supervised learning is where you have input variables (x) and an output variable (Y) and you use an algorithm to learn the mapping function from the input to the output.
Y = f(X)
The goal is to approximate the mapping function so well that when you have new input data (x) that you can predict the output variables (Y) for that data. It is called supervised learning because the process of an algorithm learning from the training dataset can be thought of as a teacher supervising the learning process. We know the correct answers, the algorithm iteratively makes predictions on the training data and is corrected by the teacher. Learning stops when the algorithm achieves an acceptable level of performance.
Reinforcement Learning (RL)
RL, known as a semi-supervised learning model in machine learning, is a technique to allow an agent to take actions and interact with an environment so as to maximize the total rewards. It is the process testing which actions are best for each state of an environment by essentially trial and error. The model introduces a random policy to start and each time an action is taken an initial amount (known as a reward) is fed to the model. This continues until an end goal is reached, e.g. you win or lose the game, where that run (or episode) ends and the game resets. As the model go through more and more episodes it begins to learn which actions are more likely to lead us to a positive outcome and therefore find the best actions in any given state, known as the optimal policy.
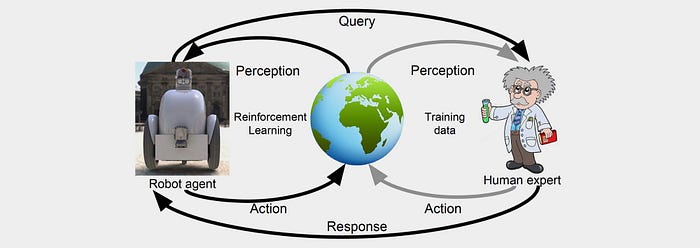
Example:
Game playing: Let’s consider a board game like Go or Chess. In order to determine the best move, the players need to think about various factors. The number of possibilities is so large that it is not possible to perform a brute-force search. If we were to build a machine to play such a game using traditional techniques, we need to specify a large number of rules to cover all these possibilities. Reinforcement learning completely bypasses this problem. We do not need to manually specify any rules. The learning agent simply learns by actually playing the game.
Named Entity Recognition
Named Entity Recognition (NER) on unstructured text has numerous uses. Entity in text may be a business, location, person name, time etc. An object that has a meaning in the query, and will have further meaning in the bot logic. NER which we have open-sourced specifically to facilitate the intelligence of Chatbots targeted at domains like personal assistance, e-commerce, insurance, healthcare, fitness, etc. There are many approaches (i.e. Generative based, Retrieval based, Heuristic based, etc.) used to build conversational bots or dialogue systems and each of these techniques make use of NER somewhere or the other in their respective pipeline as it is one of the most important modules in building the conversational bots. Chatbot NER is heuristic based that uses several NLP techniques to extract necessary entities from chat interface. In Chatbot, there are several entities that need to be identified and each entity has to be distinguished based on its type as a different entity has different detection logic.
We have classified entities into four main types i.e.
numeral- This type will contain all the entities that deal with the numeral or numbers. For example, number detection, budget detection, size detection, etc.
pattern- This will contain all the detection logic where identification can be done using patterns or regular expressions. For example, email, phone_number, PNR, etc.
temporal- It will contain detection logic for detecting time and date.
textual- It identifies entities by looking at the dictionary. This detection mainly contains detection of text (like cuisine, dish, restaurants, etc.), the name of cities, the location of a user, etc.
Returned Entities Object
In the object returned after parsing there are two fields that show information about how the pipeline impacted the entities returned. The extractor field of an entity tells you which entity extractor found this particular entity. The processors field contains the name of components that altered this specific entity.
The use of synonyms can also cause the value field not match the text exactly.
{
"text": "show me chinese restaurants",
"intent": "restaurant_search",
"entities": [
{
"start": 8,
"end": 15,
"value": "chinese",
"entity": "cuisine",
"extractor": "ner_crf",
"confidence": 0.854,
"processors": []
}
]
}Some extractors, like duckling, may include additional information. For example:
{
"additional_info":{
"grain":"day",
"type":"value",
"value":"2018-06-21T00:00:00.000-07:00",
"values":[
{
"grain":"day",
"type":"value",
"value":"2018-06-21T00:00:00.000-07:00"
}
]
},
"confidence":1.0,
"end":5,
"entity":"time",
"extractor":"ner_duckling_http",
"start":0,
"text":"today",
"value":"2018-06-21T00:00:00.000-07:00"
}The following image show how NLU works for intent and entities extraction and get back response to the user,
Intent Classification
We have new pipeline which is totally different from the standard Rasa NLU approach. It uses very little memory, handles hierarchical intents, messages containing multiple intents, and has fewer out-of-vocabulary issues. And in principle it can do intent recognition in any language.
Example: restaurant_search can be expressed many different ways:
{
"text": I’m hungry
"text": Show me good pizza spots
"text":I want to take my boyfriend out for sushi
"text":Can also be
"text":request_booking
}The standard way we’ve been doing intent classification since Rasa NLU was released is to represent sentences as a sum of word vectors, and then train a classifier on that representation. We run regular benchmarks on a dozen different datasets, where we try different word vectors and classifiers to see what really moves the needle. Mostly it’s the quality (or appropriateness) of your word vectors that matters, and using a neural net instead of a support vector machine (SVM) doesn’t make any difference.
Our new TensorFlow embedding pipeline does almost the exact opposite. It doesn’t use pre-trained word vectors, and should work on any language. The inspiration for the new method was the StarSpace paper from Facebook.
Our new embedding pipeline doesn’t use pre-trained vectors, but instead learns embedding for both the intents and the words simultaneously. And instead of training a classifier, these embedding are used to rank the similarity between an input sentence and all of the intents. This means you aren’t stuck with out-of-the-box pre-trained word vectors, but learn your own specifically for your domain.
You can also use this to model messages that contain multiple intents. For example, it’s pretty common to see a message like this: “thanks! Oh and what’s the warranty on that?”. Where a user has clearly said two different things.
With the tensorflow embedding pipeline, we can model this as two intents: thankyou and warranty. That wasn't possible with the standard SVM. Some more examples are as below,
The following image show how intent classification and entity extraction works,
Role of NLU and NLG
NLU is a sub-field of NLP which handles a narrow but complex challenge of converting unstructured inputs into a structured form which a machine can understand and act upon. So when you say “Book a hotel for me in San Francisco on 20th April 2017”, the bot uses NLU to extract date=20th April 2017, location=San Francisco and action=book hotel which the system can understand.
In this section, I would like to explain Rasa in detail and some terms used in NLP which you should be familiar with.
Intent: This tells us what the user would like to do.
Ex : Raise a complaint, request for refund etc
Entities: These are the attributes which gives details about the user’s task. Example: Complaint regarding service disruptions, refund cost etc.
Confidence Score : This is a distance metric which indicates how closely the NLU could classify the result into the list of intents.
"text": “My internet isn’t working since morning”.
- intent: “service_interruption”
- entities: “service=internet”
“duration=morning”
confidence score: 0.84 (This could vary based on your training)Here is an example to help you understand the above mentioned terms,
Rasa NLU’s job is to accept a sentence/statement and give us the intent, entities and a confidence score which could be used by our bot. Rasa basically provides a high level API over various NLP and ML libraries which does intent classification and entity extraction. These NLP and ML libraries are called as backend in Rasa which brings the intelligence in Rasa. These are some of the backends used with Rasa.
MITIE: This is an all inclusive library meaning that it has NLP library for entity extraction as well as ML library for intent classification built into it.
spaCy + sklearn — spaCy is a NLP library which only does entity extraction. sklearn is used with spaCy to add ML capabilities for intent classification.
MITIE + sklearn — This uses best of both the worlds. This uses good entity recognition available in MITIE along with fast and good intent classification in sklearn.
We can use the following type of configuration file for MITIE,
Note: If you are using `mitie` you should download a `.dat` file from https://github.com/mit-nlp/MITIE/releases/download/v0.4/MITIE-models-v0.2.tar.bz2
{
"backend": "mitie",
"mitie_file": "data/total_word_feature_extractor.dat",
"path" : "./",
"data" : "data/sitebot-data.json",
"num_threads":100,
"pipeline": "mitie"
}The following image show that how NLU and NLG works together in conversational AI chatbot using Rasa NLU,
How to create a dataset for Rasa NLU chatbot
If we want to build a chatbot to help potential users understand the Rasa offering and how it compares against other similar chatbots. So the chatbot would need to answer the following questions (sample):
- Q1: Why python?
- A1: Because of its ecosystem of machine learning tools. Head over to But I don’t code in python! for details.
- Q2: Is this only for ML experts?
- A2: You can use Rasa if you don’t know anything about machine learning, but if you do it’s easy to experiment.
- Q3: How much training data do I need?
- A3: You can bootstrap from zero training data by using interactive learning. Try the tutorials!
- Q4: How is Rasa different from other approaches?
- A4: Rather than writing a bunch of if/else statements, a Rasa bot learns from real conversations. A probabilistic model chooses which action to take, and this can be trained using supervised, reinforcement, or interactive learning.
- Q5: Where to Start
- A5: After going through the Installation, most users should start with Building a Simple Bot. However, if you already have a bunch of conversations you’d like to use as a training set, check the Supervised Learning Tutorial.
- Q6: What is Rasa NLU
- A6: You can think of Rasa NLU as a set of high level APIs for building your own language parser using existing NLP and ML libraries. The setup process is designed to be as simple as possible.
- Q7: What is Rasa Core
- A7: Rasa Core takes in structured input: intents and entities, button clicks, etc., and decides which action your bot should run next. If you want your system to handle free text, you need to also use Rasa NLU or another NLU tool.
So the intents would be something like:
intents:
- rasa_whatis
- rasa_technical
- rasa_comparison
- ... (other intents like greet, etc.)Now the NLU intent examples would be:
## intent : rasa_whatis
- What is Rasa NLU
- What is Rasa Core## intent : rasa_technical
- Why python?
- Is this only for ML experts?
- How much training data do I need?
- Where to Start## intent : rasa_comparison
- How is Rasa different from other approaches?
And the utters would be:
utter_technical_A1:
- text: "Because of its ecosystem of machine learning tools. Head over to But I don’t code in python! for details."
utter_technical_A2:
- text: "You can use Rasa if you don’t know anything about machine learning, but if you do it’s easy to experiment."
utter_technical_A3:
- text: "You can bootstrap from zero training data by using interactive learning. Try the tutorials!"
utter_comparison_A4:
- text: "Rather than writing a bunch of if/else statements, a Rasa bot learns from real conversations. A probabilistic model chooses which action to take, and this can be trained using supervised, reinforcement, or interactive learning."
utter_technical_A5:
- text: "After going through the Installation, most users should start with Building a Simple Bot. However, if you already have a bunch of conversations you’d like to use as a training set, check the Supervised Learning Tutorial."
utter_whatis_A6:
- text: "You can think of Rasa NLU as a set of high level APIs for building your own language parser using existing NLP and ML libraries. The setup process is designed to be as simple as possible."
utter_whatis_A7:
- text: "Rasa Core takes in structured input: intents and entities, button clicks, etc., and decides which action your bot should run next. If you want your system to handle free text, you need to also use Rasa NLU or another NLU tool."Dialog Handling with Rasa Core
Natural Language Generation
The challenge with human language is that it will not confirm to a pre-defined format or script. At different points in time the same human may type different messages for the same intent. Plus, many a times humans are abstract and ambiguous in conversations. How does the chatbot handle such situations?
A chatbot possessing NLG ability would mean that the chatbot knows what exact and clear response (message) to generate for a corresponding user message.
Take an example like ‘I want to travel from London to New York’,the chatbot would have to understand that for booking a flight we also need date and time of the travel and thus ask the user for a specific date of travel, time of travel, return journey etc.
However, if the user had already provided this information in the message then the chatbot should not ask for the same information again.
In case of if user doesn’t provide the date and time of travel then the chatbot should respond like ‘Thank you Mr. ABC for your inquiry. Could you provide the date and time of travel?’
But, If user already provide the detail then the chatbot should respond like ‘‘Thank you Mr. ABC for your enquiry. Let me check for available flights and get back soon’
Here we can see that the response must be coherent, meaningful, contextual, complete, non-repetitive and clear. This mandates that the response cannot be static but must be dynamic.
Basically, there are two ways that any chatbot can generate a response. One of the ways this has been solved is by using a Dialog management system. Another way is for different input messages the predictive model can be trained to decide what to say next, contextually. Rasa Core is one such Dialog Management system for NLG.
Recent research in NLG has uncovered Deep Learning algorithms, especially Neural Dialog Generation Models such as Sequence to Sequence, that are more effective in predicting responses to natural language conversations. This would tremendously improve the comprehension abilities of machines and would also enable chatbots to handle question answering problems.
RASA also offers a built-in templated based NLG. However, it also allows you to connect to an external HTTP server for NLG. What happens in that server is up to you, and it could be a neural network based NLG server, but that needs to be done by you.
Example of template driven NLG,
templates:
utter_greet:
- "hey there {name}!" # variable will be filled by slot with the same name or by custom code
utter_goodbye:
- "goodbye 😢"
- "bye bye 😢" # multiple templates will allow the bot to randomly pick from them
utter_default:
- "default message"Advance NLG: Neural networks and Machine Learning
In this type of response, bot will learn to predict actions and respond to the user which is based on past dialogue history and the responses to send back to the user are generated outside the Rasa Core.
Sometimes, bot will call an external HTTP server with the post request. For configuration you need to create some endpoints.yml type of file and have to pass it either to the run or server script.
The core will contact your server with information from the the conversation, including the user utterance, intent and slots filled. Your server then would have a neural net based NLG (developed by you) which would return the text that the bot should display to the user.
How LSTM can control dialog system using Supervised and Reinforcement Learning Algorithm
Designing conversational systems is a challenging task and one of the original goals of Artificial Intelligence. For decades, conversational agent design was dominated by systems that rely on knowledge bases and rule-based mechanisms to understand human inputs and generate reasonable responses. Data-driven approaches emphasize learning directly from corpora of written or spoken conversations. Recently, this approach gained momentum because of data abundance, increasing computational power, and better learning algorithms that automate the feature engineering process.
The main component of the model is a recurrent neural network (an LSTM), which maps from raw dialog history directly to a distribution over system actions. The LSTM automatically infers a representation of dialog history, which relieves the system developer of much of the manual feature engineering of dialog state. The purpose of LSTM is to take actions in the real world on behalf of the user, it can be optimized using supervised learning (SL), where a domain expert provides example dialogs which the LSTM should imitate; or using reinforcement learning (RL), where the system improves by interacting directly with end users.
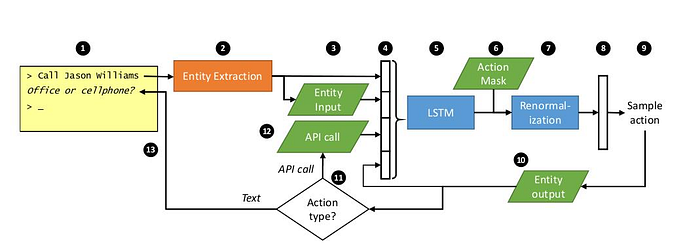
The system action is mapped into a system reply at the semantic level, and this is subsequently passed to the natural language generator for output to the user. The semantic reply consists of three parts: the intent of the response, (e.g. inform), which slots to talk about (e.g. area), and a value for each slot (e.g. east). To ensure tractability, the policy selects a from a restricted action set which identifies the intent and sometimes a slot , any remaining information required to complete the reply is extracted using heuristics from the tracked belief state.
Dialogue policy optimization can be seen as the task of learning to select the sequence of responses (actions) at each turn which maximizes the long term objective defined by the reward function. This can be solved by applying either value-based or policy-based methods.
Basically, we use two kind of model for dialogue generation,
i. Ranking Responses Oriented to Conversational Relevance using Neural network
ii. Reinforcement learning for dialogue generation
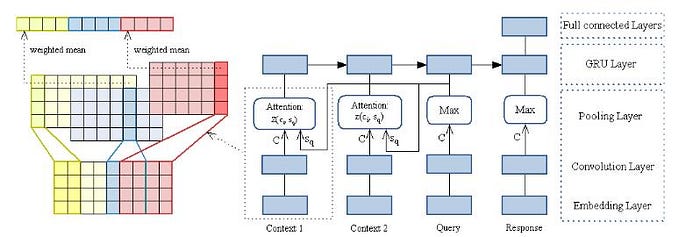
The even more essential challenge chat-bots have to face is to guarantee the semantic and logic continuity of conversations, that is, a response from bots should be relevant with both the adjacent query and the corresponding short conversation history. Actually, such “context-aware” chatting ability is the critical feature of a human-like chat-bot, thus much attention has been paid on this task. The basic requirement for chat-bots is to semantically understand conversations like humans, which is abstracted as the conversation modeling problem.
The following image is basic architecture for conversation modeling,
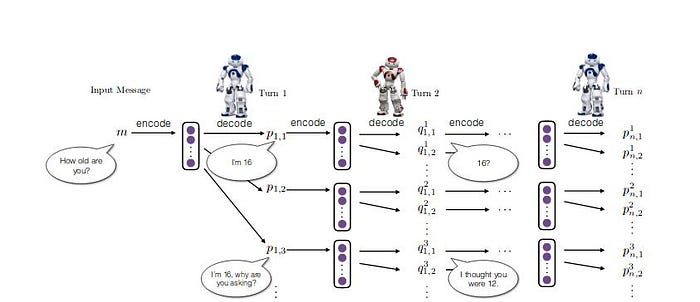
In Reinforcement learning, It is very useful when we want our model to do more than produce a probable human label. The following image shows how the conversation happen while we use reinforcement learning for dialogue handling,
Finally, we can say that all above such kind of stuff are the basic concept of how dialogue handling with Rasa core works in conversational AI chatbot. Hence we can say that Rasa-NLU provides a good platform that is fast and customizable, a small business will face a lot of technological hurdles to use it on a production system.
Script to create conversational AI chatbot by using Rasa NLU and Rasa core with integration with Flask
I have taken one dataset for python event lecture series where the bot will give the information regarding lecture event,
The following image show that how we can train the datase with rasa nlu trainer,

Folder Structure
After that we can train the dataset by using following command as below,
“python -m rasa_nlu.train -c AI-engine/config_spacy.json — data AI-engine/data/sitebot-data.json”
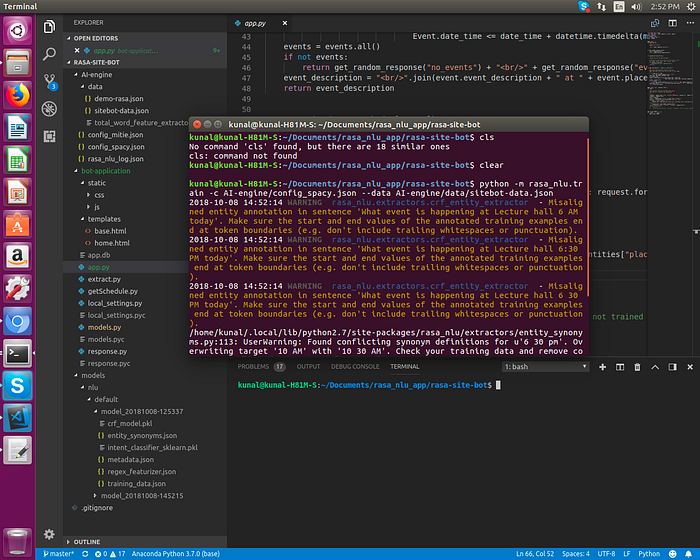
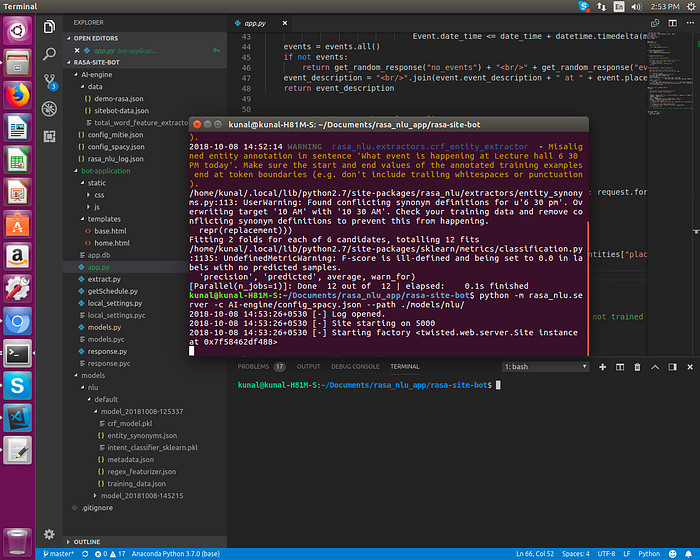
We start the server for hosting this model for your chatbot application to use, for this we use following command,
“python -m rasa_nlu.server -c AI-engine/config_spacy.json — path ./models/nlu/”
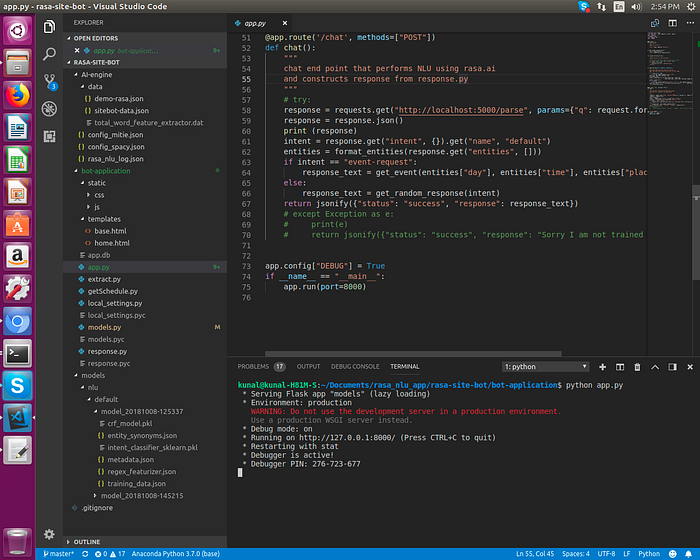
Finally, we will start the chatbot application y using followng command
“python app.py”
Final chatbot output,
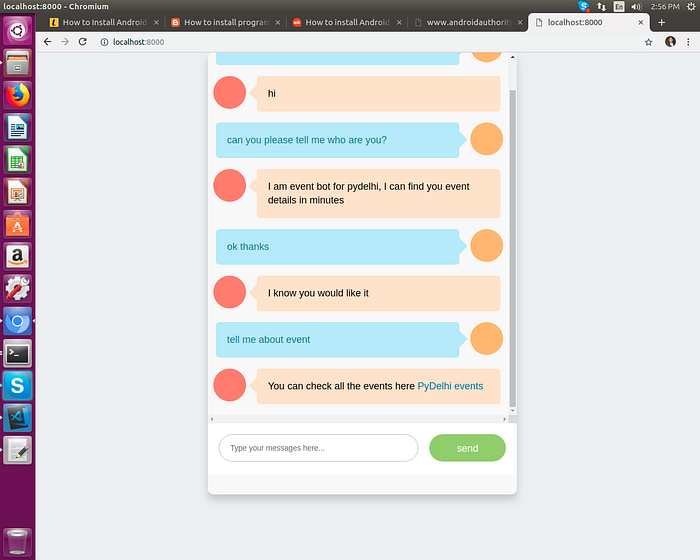
Gif file of Chatbot
References
i. Rasa: Open Source Language Understanding and Dialogue Management (paper link)
ii. Rasa NLU documentation (Link)
iii. Rasa Core documentation (Link)
iv. Ranking Responses Oriented to Conversational Relevance in Chat-bots (paper link)
v. End-to-end LSTM-based dialog control optimized with supervised and reinforcement learning (paper link)
vi. Deep Reinforcement Learning for Dialogue Generation (paper link)
vii. Conversational Contextual Cues: The Case of Personalization and History for Response Ranking (paper link)
viii. A computational model for automatic generation of domain-specific dialogues using machine learning (paper link)
ix. Dialogue Generation using Reinforcement Learning and Neural Language Models (paper link)
