MLOps on GCP — Understand basic ML Workflow Management up-to Production-Ready

MLOps, CI/CD Pipeline, GCP, Kubeflow, Kubernates, Jenkins, TFX, MLFlow
Introduction
In this blog, we will discuss the Machine Learning workflow in the Production environment where the machine learning engineers automatically orchestrate the entire data science flow smoothly deployment lifecycle and process.
Machine Learning and Data Science practices have been widely accepted for transforming business decisions and solving complex business problems by a large number of companies as a potential source. In generic data science problem statements, there can be many common parts involved like collecting data, building ETL pipelines, performing exploratory data analysis, fixing data insufficiencies, doing feature engineering, trying with several models, performing hyperparameter optimizations, creating inference layer, creating service layer to serve the model, monitoring the model in production and doing online learning if possible.
In the Figure below, We can see that the Manual Cycle of Continuous delivery and automation pipelines in machine learning,

In this article, we will discuss some of the best open-source tools to enable end-to-end production-ready data science workflow management that can be used to build a CI/CD and CT pipeline for any data science problem.
Basically, the MLOps has 4 core principles are listed below,
i. Continuous Integration (CI): In this stage, the continuous testing and validating of code, data, and models takes place.
ii. Continuous Delivery (CD): In this stage, the delivery of an ML training pipeline that automatically deploys another ML model prediction service takes place.
iii. Continuous Training (CT): In this stage, the automatically retraining ML models for redeployment take place.
iv. Continuous Monitoring (CM): In this stage, the monitoring production data and model performance metrics take place.
Google Cloud Platform
The Google Cloud Platform was started in 2011 and since its beginning, it has accumulated many important partners such as Airbus, Coca-Cola, HTC, Spotify, etc. most notably Equinix, Intel and Red Hat. Google Cloud Platform also offers storage options such as: i. MySQL Database ii. Cloud Datastore iii. Cloud Storage & each of these storages are available at separate pricing slabs calculated in the units of GB per month.
The services provided by Google Cloud Platform are:
Compute Storage and Databases Networking Big Data Machine Learning Management Tools Developer Tools Identity & Security
The following diagram shows an example of the architecture that provides the MLOps capabilities. The environment includes a set of integrated Google Cloud services.

We will discuss the details of all four stages of CI/CD and CT pipeline in the next section. We will discuss step by step process for deployment of Machine Learning & Data Science problems statement into the production environment as below,
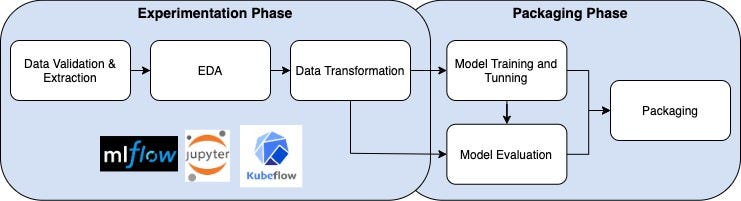
Step 01: Experimentation & Packaging
In order to make progress in the experimentation & packaging stage to cultivate a machine learning / AI solution to a problem, we will need some tools to properly manage the initial experiments, track them, and get a clearer picture of what worked, whatnot, and by how much. Experiment tracking is a part (or process) of MLOps focused on collecting, organizing, and tracking model training information across multiple runs with different configurations (hyperparameters, model size, data splits, parameters, and so on).

The following tools could be part of this phase,
a. MLFlow
MLflow by Databricks is an open-source ML lifecycle management platform. It has tools to monitor your ML model during training and while running, along with the capability to store models, load models in production code, and build pipelines. It is used to track various parameters, features, metrics, epoch/iteration, box visualizations as well as to take a quick glance at various experiments and their results. MLFlow also provides model versioning and Tracking.
The MLFlow components are,

b. Kubeflow
Kubeflow was initially based on Google’s internal way to deploy TensorFlow models called (TFX)TensorFlow Extended. The functionality of Kubeflow pipelines is to track each experiment and their runs, compare multiple runs, as well as providing a Kubernetes infrastructure to quickly perform lots of parallels experiments with scale. Kubeflow Pipelines is the component in Kubeflow that manages and orchestrates the end-to-end ML workflows. Steps in an ML workflow are wrapped as components in Kubeflow Pipelines, such as data preprocessing, data transformation, and model training. After being packaged as Docker images, these components are reusable across pipelines in a containerized way. It is the ultimate ML platform designed to enable using ML pipelines to orchestrate complex workflows running on Kubernetes. Kubernetes is an open-source cluster manager to arrange Docker containers among a mass of virtual or physical machines, which is increasingly adopted in cloud computing. Besides creating, monitoring and scheduling containers to execute programs and run the software, Kubernetes also supports the ability to build custom resources (CRs) according to declarative specifications. Kubeflow platform in CI/CD procedures when the files change in the code repository, while the running of pipelines can be triggered on schedule or through the message sent by cloud storage when new data arrives.
In the below figure, we will see the overview of ML Pipeline Platform where we can the difference between CI/CD pipeline & Kubeflow pipeline,

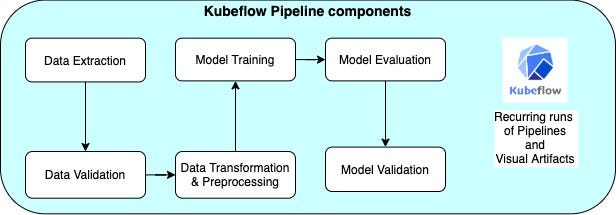
The next diagram adds Kubeflow to the workflow, showing which Kubeflow components are useful at each stage in the production phase:

Some of the key features of Kubeflow:
i. To manage and track experiments, runs, and jobs, Kubeflow provides a good user interface.ii.Multi-framework integration & SDK to interact with the system using Notebooks.iii. To swiftly build end-to-end solutions you can re-use all the provided components & pipelines.iv. Pipelines in Kubeflow are either a core component of Kubeflow or a standalone installation.v. Perfect fit for every Kubernetes user. Wherever you’re running Kubernetes, you can run Kubeflow.
c. TensorFlow Extended (TFX)
A TFX pipeline is a sequence of components that implement an ML pipeline that is specifically designed for scalable, high-performance machine learning tasks. The main motivation behind Google’s development of TensorFlow eXtended (TFX) was to reduce the time to produce a machine learning model from months to weeks. Their engineers and scientists struggled because ‘the actual workflow becomes more complex when machine learning needs to be deployed in production.
The architecture of Google’s TFX is shown below,

The Components are built using TFX libraries which can also be used individually. List of open-source TFX components are as below,

Key components:
i. TensorFlow Data Validation — Explores & Validates data used for machine learning.ii. TensorFlow Transformation — Creates transformation graphs that are consistently applied during training and serving to make full-pass analysis phases on the available data.iii. TensorFlow Model Analysis — Computes full-pass & sliced model metrics on massive datasets, and analyzes them using libraries and visualization elements.iv. TensorFlow Serving — TF Serving is designed for production environments. It’s a flexible, high-performance serving system for machine learning models.
c. Jupyter Notebook
It is used for data cleaning to building some high performant models.
Step 02: Model Versioning
In the re-iteration process, we need to add new features or functionalities or supports to our solution and the package version that we will have initially and the one with new changes must be properly versioned so that multiple team members can have clear visibility of the changes that others are working and can be properly reviewed by the team to reduce the possibility of something that may go wrong later. Model versioning is more important because of following reasons like finding the best model, failure tolerance, increased complexity and file dependencies, gradual staged deployment, AI/ML governance etc.
If you’ve spent time working with machine learning, one thing is clear: It’s an iterative process. There are so many different parts of your model like how you use your data, hyperparameters, parameters, algorithm choice, architecture and the optimal combination of all of those is the holy grail of machine learning.
The basic structure of clear visibility of team members as shown below,

For this we can use following tools,
a. Git
It is a free and open-source distributed version control system that can be used to maintain the versioning of packaged codes. Some of the most widely used web-based repositories that can be used to host and maintain a backup of the codes can be GitHub, GitLab, etc
Step 03: CI (Continuous Integration)
As we have discussed above about Kubeflow pipelines as a Kubernetes environment to train and deploy our models, we will be having multiple components in our pipeline like data acquisition, data preprocessing, continuous trainer, model trainer, etc. Each component of a Kubeflow pipeline will be a container and thus we need docker image builds for all those container images properly versioned and maintained in some repository like AWS ECR. Now to build and push these images to their respective repositories, we will have to include this step into our CI trigger. Apart from the docker image building and pushing, our CI will also contain the tests that must be run as the first part of the CI trigger in order to check whether the newly committed changes are stable or not.
The following diagram shows the implementation of the ML pipeline using CI/CD, which has the characteristics of the automated ML pipelines setup plus the automated CI/CD routines.

The above MLOps setup includes the components like Source control, Test and build services, Deployment services, Model registry, Feature store, ML metadata store, ML pipeline orchestrator.
The following diagram shows the stages of the CI/CD automated ML pipeline:

The recommend tool for this phase is,
a. Jenkins
It is an automation server that can be easily used to reliably build the docker images for our Kubeflow pipeline component as well as for running the tests over newly committed codes. Jenkins is typically used in tandem with a source control management (SCM) tool like Github. Jenkins projects are often configured to trigger builds or run scripts when people push or merge branches in their repo. However, there are a number of available hooks. It can also be used to automate:
i. Building/tagging/pushing of software (Docker images)
ii. Unit tests, integration tests, etc…
iii. Deployment to dev/stage/prod environments (if you use it for CD)
Step 04: CT (Continuous Training)
In this phase we will discuss about how to automatically orchestrate the machine learning model training over Kubernetes cluster via Kubeflow Pipelines.

Some common components of this phase are,
a. Data acquisitionThis component will acquire the raw data that can lie within any cloud servers like AWS S3 bucket or Google cloud storage or Azure blob, etc.b. Data PreprocessorThis component will preprocess the acquired data using whatever preprocessing steps that may have been developed as a re-iteration phase or experimentation phase.c. Continuous Trainer (CT)One of the solutions could be to use currently supported periodic trigger to periodically check some cloud-based buckets like S3 that, is there any training ticket that has been raised or not? If yes then CT can execute the next model trainer component otherwise it can skip the training for then.d. Model TrainerThis component will take the preprocessed data and do the model training over that data. While Kubeflow pipelines do provide us the feature to track experiments and their multiple runs along with some out of the box support for visualizations and all, but we can leverage MLFlow here to keep track of the parameters, metrics as well as the best performing models very easily. In order to orchestrate the pipeline run, we will need to supply .yml configuration in a domain-specific language (DSL) to the Kubeflow pipeline interface to create resources for each of the components as required and orchestrate the run.
A high-level view of Kubefolw pipeline graph is shown below,

In this phase we use following tools,
a. Kubeflow
A free and open-source machine learning platform designed to enable using machine learning pipelines to orchestrate complicated workflows running on Kubernetes. The detail about this we have already discussed above.
b. MLFlow
An open-source platform for the end-to-end machine learning lifecycle. We have already discussed about this in this blog above.
Step 04: CD (Continuous Delivery)
In this stage, we put our trained model into production-ready environment, we need to manage the complexity of auto-scaling, networking, health checking, and server configuration to bring cutting edge serving features like GPU autoscaling, scale to zero, and canary rollouts to our ML deployments. So in order to achieve that, we can leverage Kubeflow native KFServing. KFServing enables serverless inferencing on Kubernetes and provides high performant and easy abstraction interfaces for common machine learning frameworks like TensorFlow, XGBoost, scikit-learn, PyTorch, and ONNX.
KFServing extends the Kubernetes API with objects of kind InferenceService. In order to serve an ML model, a new object needs to be created including required information in its specification. This required information concerns the predictor component and includes the location where the model is stored and the model server used to run the model.
The architecture of KFServing is shown below,

This Kubeflow pipeline part can have predominantly two components:
a. Continuous DeliveryThis component will decide whether to deploy the model or not. Since Kubeflow at this point in time does not support event-based triggers to run a pipeline so we can again use the previously discussed CT-like workaround of using a Kubeflow pipeline periodic trigger to periodically check some cloud-based buckets like S3 that, is there any deploying ticket that has been raised or not? If yes then CD can execute the next model inference component otherwise it can skip the deployment for then.
and another component is,
b. Model InferenceAs the name suggests, this will create a KFServing model deployment over some port in order to serve the model. As this deployment port will be available only to the internal environment, so no request can reach there. To solve this, we will need to configure the Ingress gateway using an Istio gateway as well as Knative Serving needs to be there as well for KFServing.
The runtime execution graph of the pipeline shown below the example pipeline’s runtime execution graph in the Kubeflow Pipelines UI:

Recommended Tools:
a. Kubeflow
We have already discussed above.
b. MLFlow(Optional)
We have already discussed above.
Step 05: Monitoring
In this stage, we monitor the inference lifecycle of the model while in production. We can store real-time inference logs with various details about confidence score for some predictions, IP-address of the clients using services, etc to some time-series database like influx DB and visualize it in real-time through some tools like grafana. This can account for any unexpected behaviors and can help in mitigating the effects as early as possible.
Key functionalities in model monitoring include the following:
i. Measure model efficiency metrics like latency and serving-resource utilization.ii. Detect data skews, including schema anomalies and data and concept shifts and drifts.iii. Integrate monitoring with the model evaluation capability for continuously assessing the effectiveness performance of the deployed model when ground truth labels are available.
Recommended Tools:
a. InfluxDB
This is time-series database. We can store real-time inference logs into this DB for some real-time analysis.
b. Grafana
We can use grafana to get a real-time view of the ML model inferencing results and its usage behaviors.
Overall CI/CD Pipeline
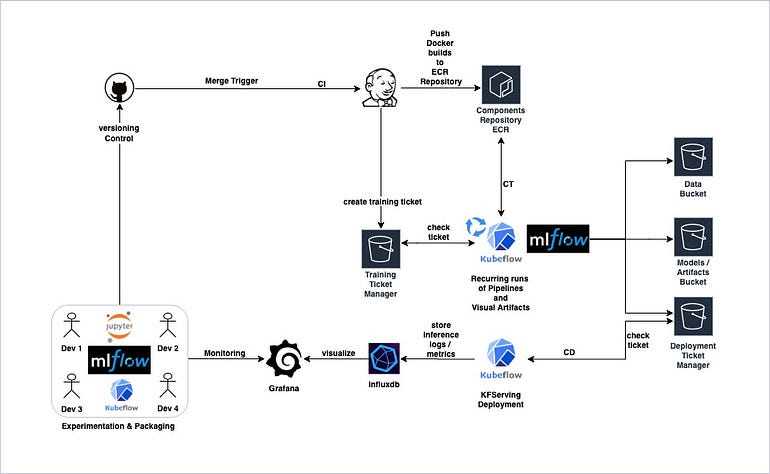
Now it’s time to concludes all the phases that makes a production-ready MLOps environment for managing the entire data science project lifecycle. The main components required for the development and implementation of MLOps pipeline automation with CI/CD routines are Business problem analysis, Dataset features and storage, ML analytical methodology, Pipeline CI components, Pipeline CD components, Automated ML triggering, Model registry storage, Monitoring and performance, Production ML service & in figure shown below,

The below figure is the high-level solution architecture that shows where to put what tools and their communication flow leveraging Kubernetes infrastructure.

The phase-wise MLOps and their responsibility is shown in next figure,

The high-level overview of CI/CD for ML with Kubeflow pipelines on GCP environment is shown below,

Summary
In final conclusion of this blog, we concludes all the phases that makes a production-ready MLOps environment for managing the entire data science project lifecycle. We can see that machine learning models lifecycle is different and more complex than traditional software development; it requires extensive work with data extraction, preparation and verification, infrastructure configuration, provisioning, post-production monitoring, and enhancements.
References
i. MLOps — When Training The Best Model Is Not Enough
ii. MLOps — Building a Production Ready Data Science Workflow management
iii. A Tour of End-to-End Machine Learning Platforms
iv. Applying DevOps Practices of Continuous Automation for Machine Learning
v. How to carry out CI/CD in Machine Learning (“MLOps”) using Kubeflow ML pipelines
vii. MLOps: Continuous delivery and automation pipelines in machine learning
viii. Architecture for MLOps using TFX, Kubeflow Pipelines, and Cloud Build
ix. Setting up an MLOps environment on Google Cloud
x. Introducing MLflow: an Open Source Machine Learning Platform

{kind=link}
{kind=link}
{kind=link}
{kind=link}