“SparkTorch” A High-Performance Distributed Deep Learning Library: Step-by-Step Training of PyTorch Network on Hadoop YARN & Apache Spark in Your Local Machine

Distributed Computing, Apache Spark, Apache Hadoop Map Reduce, Apache Hadoop YARN, HDFS, SparkTorch, PyTorch
A. Introduction
In this article, I will explain step by step process of “Distributed Training of PyTorch Network on Hadoop YARN & Apache Spark in Your Local Machine”. For this, we will use the mnist_train.csvfile. The mnist_train.csv file contains the 60,000 training examples and labels. The mnist_test.csv contains 10,000 test examples and labels. In this dataset each row consists of 785 values: the first value is the label (a number from 0 to 9) and the remaining 784 values are the pixel values (a number from 0 to 255). Here we will consider only the train dataset. Firstly we will discuss some basic stuff like Distributed computing, Apache Spark, Apache Hadoop, YARN, HDFS & SparkTorch.
a. Distributed Computing
In Distributed computing system there are multiple system processors that can communicate with each other on the message that is sent over the network, but in the case of parallel computing systems, as the number of processors increases, with enough parallelism available in applications, through the shared memory, such systems easily beat sequential systems in performance. In parallel computing systems, the processors can also contain their own locally allocated memory, which is not available to any other processors.
In the figure below, there is a Comparison of Distributed vs Parallel Computing:

Reason for building distributed system not just the parallel system:
a. Scalability: The distributed systems are more scalable as compare to parallel system with the increasing number of processors it doesn't have problem with shared memory.b. Reliability: As compare to parallel systems, the distributed computing having much more impact of the failure of any single subsystem or a computer on the network of computers defines the reliability of such a connected system.c. Data Sharing: Data sharing provided by distributed systems is similar to the data sharing provided by distributed databases. d. Resource Sharing: In distributed computing the resource sharing facility is much easy as compare to other system.e. Heterogeneity & Modularity: The Distributed systems are flexible enough such that it can accept a new heterogeneous processor to be added into it and one of the processors to be replaced or removed from the system without affecting the overall system processing capability. f. Geographic Construction: The geographic placement of different subsystems of an application may be inherently placed as distributed. Local processing may be forced by the low communication bandwidth more specifically within a wireless network.g. Economic: With the evolution of modern computers, high-bandwidth networks and workstations are available at low cost, which also favors distributed computing for economic reasons.
b. Apache Hadoop
The design Hadoop Distributed File System (HDFS) is in such a way so that it can run on commodity hardware. The HDFS is highly fault-tolerant and is designed to be deployed on low-cost hardware. It provides high throughput access to application data and is suitable for applications that have large data sets. HDFS relaxes a few Portable Operating System Interface (POSIX) requirements to enable streaming access to file system data. HDFS was originally built as infrastructure for the Apache Nutch web search engine project. HDFS is now an Apache Hadoop subproject.
Hadoop — Different Modes of Operation
As we all know Hadoop is an open-source framework that is mainly used for storage purposes and maintaining and analyzing a large amount of data or datasets on the clusters of commodity hardware, which means it is actually a data management tool. Hadoop also posses a scale-out storage property, which means that we can scale up or scale down the number of nodes as per are a requirement in the future which is really a cool feature.
Hadoop can be installed in 3 different modes: Standalone mode, Pseudo-Distributed mode, and Fully-Distributed mode. Standalone mode is the default mode of operation of Hadoop and it runs on a single node ( a node is your machine).
The type of mode operations in Apache Hadoop is shown below,

In Standalone Mode, none of the Daemon will run i.e. Namenode, Datanode, Secondary Name node, Job Tracker, and Task Tracker. We use job-tracker and task-tracker for processing purposes in Hadoop1. For Hadoop2 we use Resource Manager and Node Manager. Standalone Mode also means that we are installing Hadoop only in a single system. By default, Hadoop is made to run in this Standalone Mode or we can also call it the Local mode. We mainly use Hadoop in this Mode for the Purpose of Learning, testing, and debugging.
In Pseudo-distributed Mode we also use only a single node, but the main thing is that the cluster is simulated, which means that all the processes inside the cluster will run independently from each other. All the daemons that are Namenode, Datanode, Secondary Name node, Resource Manager, Node Manager, etc. will be running as a separate process on separate JVM(Java Virtual Machine) or we can say run on different java processes that is why it is called a Pseudo-distributed.
The Fully Distributed Mode (Multi-Node Cluster) is the most important one in which multiple nodes are used few of them run the Master Daemon’s that are Namenode and Resource Manager and the rest of them run the Slave Daemon’s that are DataNode and Node Manager. Here Hadoop will run on the clusters of Machines or nodes. Here the data that is used is distributed across different nodes. This is actually the Production Mode of Hadoop let’s clarify or understand this Mode in a better way in Physical Terminology.
The file system replicate — or copies — each piece of data multiple times and distributes the copies to individual nodes, placing at least one copy on a different server rack than the other copies.

NameNode and DataNodes
In an HDFS cluster there are two types of nodes operating in a master−slave pattern:
- NameNode (Master)
2. Number of DataNodes (slaves/workers)
Basically, the Apache Hadoop comprises five different daemons and each of these daemons runs its own JVM- i) NameNode, ii) DataNode, iii) Secondary NameNode, iv) JobTracker, and v)TaskTracker.
The NameNode and DataNode are daemons that store data and metadata i.e.,, comes under the HDFS layer, and JobTracker and TaskTracker, which keeps track and actually executes the job, comes under the MapReduce layer, as shown in Fig. below. The Hadoop cluster is comprised of multiple slave nodes and a master node. The master node runs the master daemons for each layer i.e., NameNode for the HDFS storage layer, and JobTracker for the MapReduce processing layer. The rest of the machines will run the “slave” daemons: DataNode for the HDFS layer and TaskTracker for MapReduce layer.

An HDFS cluster consists of a single NameNode, a master server that manages the file system namespace and regulates access to files by clients. In addition, there are a number of DataNodes, usually, one per node in the cluster, which manage storage attached to the nodes that they run on. HDFS exposes a file system namespace and allows user data to be stored in files. Internally, a file is split into one or more blocks and these blocks are stored in a set of DataNodes. The NameNode executes file system namespace operations like opening, closing, and renaming files and directories. It also determines the mapping of blocks to DataNodes. The DataNodes are responsible for serving read and write requests from the file system’s clients. The DataNodes also perform block creation, deletion, and replication upon instruction from the NameNode.

The commodity machines (The idea of driving Commodity Hardware in Hadoop is straightforward: you have a few servers, and you convey the load among them.) typically run a GNU/Linux operating system (OS) on which the NameNode & DataNode are designed to run. HDFS is built using the Java language; any machine that supports Java can run the NameNode or the DataNode software. Usage of the highly portable Java language means that HDFS can be deployed on a wide range of machines. A typical deployment has a dedicated machine that runs only the NameNode software. Each of the other machines in the cluster runs one instance of the DataNode software. The architecture does not preclude running multiple DataNodes on the same machine but in a real deployment that is rarely the case.
The functionality of NameNode (Master in Hadoop Cluster) is listed below,
i. Stores metadata of actual data. E.g. Filename, Path, No. of Data Blocks, Block IDs, Block Location, No. of Replicas, Slave related configuration
ii. Manages File system namespace.
iii. Regulates client access requests for the actual file data files.
iv. Assign work to Slaves(DataNode).
v. Executes file system namespace operations like opening/closing files, renaming files, and directories.
vi. As the Name node keeps metadata in memory for fast retrieval, a huge amount of memory is required for its operation. This should be hosted on reliable hardware.
The functionality of DataNode (Slave in Hadoop Cluster) is listed below,
i. Actually stores Business data.
ii. This is the actual worker node where Read/Write/Data processing is handled.
iii. Upon instruction from Master, it performs creation/replication/deletion of data blocks.
iv. As all the Business data is stored on DataNode, a huge amount of storage is required for its operation. Commodity hardware can be used for hosting DataNode.

The existence of a single NameNode in a cluster greatly simplifies the architecture of the system. The NameNode is the arbitrator and repository for all HDFS metadata. The system is designed in such a way that user data never flows through the NameNode.
The File System Namespace
In HDFS traditional hierarchical file organization a user or an application can create directories and store files inside these directories. The file system namespace hierarchy is similar to most other existing file systems; one can create and remove files, move a file from one directory to another, or rename a file. HDFS does not yet implement user quotas. It does not support hard links or soft links. The NameNode maintains the file system namespace. Any change to the file system namespace or its properties is recorded by the NameNode. An application can specify the number of replicas of a file that should be maintained by HDFS. The number of copies of a file is called the replication factor of that file. This information is stored by the NameNode.
In the large cluster, the HDFS is designed to reliably store very large files across machines It stores each file as a sequence of blocks; all blocks in a file except the last block are the same size. The blocks of a file are replicated for fault tolerance. The block size and replication factor are configurable per file. An application can specify the number of replicas of a file. The replication factor can be specified at file creation time and can be changed later. Files in HDFS are write-once and have strictly one writer at any time.
The NameNode makes all decisions regarding the replication of blocks. It periodically receives a Heartbeat and a Blockreport from each of the DataNodes in the cluster. Receipt of a Heartbeat implies that the DataNode is functioning properly. A Blockreport contains a list of all blocks on a DataNode.

Size of Cluster
A Hadoop cluster size is a set of metrics that defines the storage and compute capabilities to run Hadoop workloads, namely :
i. Number of nodes: number of Master nodes, number of Edge Nodes, number of Worker Nodes.
ii. Configuration of each type node: number of cores per node, RAM and Disk Volume.
Hadoop Cluster Architecture
Hadoop clusters are composed of a network of master and worker nodes that orchestrate and execute the various jobs across the Hadoop distributed file system. The master nodes typically utilize higher quality hardware and include a NameNode, Secondary NameNode, and JobTracker, with each running on a separate machine. The workers consist of virtual machines, running both DataNode and TaskTracker services on commodity hardware, and do the actual work of storing and processing the jobs as directed by the master nodes. The final part of the system are the Client Nodes, which are responsible for loading the data and fetching the results.

i. Master nodes are responsible for storing data in HDFS and overseeing key operations, such as running parallel computations on the data using MapReduce.
ii. The worker nodes comprise most of the virtual machines in a Hadoop cluster and perform the job of storing the data and running computations. Each worker node runs the DataNode and TaskTracker services, which are used to receive the instructions from the master nodes.
iii. Client nodes are in charge of loading the data into the cluster. Client nodes first submit MapReduce jobs describing how data needs to be processed and then fetch the results once the processing is finished.
Hadoop MapReduce
MapReduce is a Hadoop framework used for writing applications that can process vast amounts of data on large clusters. It can also be called a programming model in which we can process large datasets across computer clusters. This application allows data to be stored in a distributed form. It simplifies enormous volumes of data and large-scale computing.
Hadoop divides the job into tasks. There are two types of tasks:
i. Map tasks (Splits & Mapping)
ii. Reduce tasks (Shuffling, Reducing)
In the map job, we split the input dataset into chunks. Map task processes these chunks in parallel. In the map, we use outputs as inputs for the reduced tasks. Reducers process the intermediate data from the maps into smaller tuples, which reduces the tasks, leading to the final output of the framework.
The MapReduce framework enhances the scheduling and monitoring of tasks. The failed tasks are re-executed by the framework. This framework can be used easily, even by programmers with little expertise in distributed processing. MapReduce can be implemented using various programming languages such as Java, Hive, Pig, Scala, and Python.
The complete execution process (execution of Map and Reduce tasks, both) is controlled by two types of entities called a Jobtracker: Acts as a master (responsible for complete execution of submitted job) and Multiple Task Trackers: Acts like slaves, each of them performing the job.
For every job submitted for execution in the system, there is one Jobtracker that resides on Namenode and there are multiple task-trackers that reside on Datanode.
The MapReduce architecture shows in the figure below,

A job is divided into multiple tasks which are then run onto multiple data nodes in a cluster. It is the responsibility of the job tracker to coordinate the activity by scheduling tasks to run on different data nodes. Execution of individual tasks is then to look after by task tracker, which resides on every data node executing part of the job. The Task tracker’s responsibility is to send the progress report to the job tracker. In addition, the task tracker periodically sends a ‘heartbeat’ signal to the Jobtracker so as to notify him of the current state of the system. Thus job tracker keeps track of the overall progress of each job. In the event of task failure, the job tracker can reschedule it on a different task tracker.
In the MapReduce architecture, clients submit jobs to the MapReduce Master. This master will then sub-divide the job into equal sub-parts. The job parts will be used for the two main tasks in MapReduce: mapping and reducing. The developer will write logic that satisfies the requirements of the organization or company. The input data will be split and mapped. The intermediate data will then be sorted and merged. The reducer that will generate a final output stored in the HDFS will process the resulting output.
How job trackers and task trackers work
Every job consists of two key components: mapping tasks and reduces tasks. The map task plays the role of splitting jobs into job parts and mapping intermediate data. The reduced task plays the role of shuffling and reducing intermediate data into smaller units. The job tracker acts as a master. It ensures that we execute all jobs. The job tracker schedules jobs that have been submitted by clients. It will assign jobs to task trackers. Each task tracker consists of a map task and reduces the task. Task trackers report the status of each assigned job to the job tracker. The following diagram summarizes how job trackers and task trackers work.

Working of Mapping, Shuffling & Reducing Phases
The MapReduce program is executed in three main phases: mapping, shuffling and reducing. There is also an optional phase known as the combiner phase.
Mapping Phase
This is the first phase of the program. There are two steps in this phase: splitting and mapping. A dataset is split into equal units called chunks (input splits) in the splitting step. Hadoop consists of a RecordReader that uses TextInputFormat to transform input splits into key-value pairs.
The key-value pairs are then used as inputs in the mapping step. This is the only data format that a mapper can read or understand. The mapping step contains a coding logic that is applied to these data blocks. In this step, the mapper processes the key-value pairs and produces an output of the same form (key-value pairs).
Shuffling phase
This is the second phase that takes place after the completion of the Mapping phase. It consists of two main steps: sorting and merging. In the sorting step, the key-value pairs are sorted using the keys. Merging ensures that key-value pairs are combined.
The shuffling phase facilitates the removal of duplicate values and the grouping of values. Different values with similar keys are grouped. The output of this phase will be keys and values, just like in the Mapping phase.
Reducer phase
In the reducer phase, the output of the shuffling phase is used as the input. The reducer processes this input further to reduce the intermediate values into smaller values. It provides a summary of the entire dataset. The output from this phase is stored in the HDFS.
The following diagram shows an example of a MapReduce with the three main phases. Splitting is often included in the mapping stage.

Combiner phase
This is an optional phase that’s used for optimizing the MapReduce process. It’s used for reducing the pap outputs at the node level. In this phase, duplicate outputs from the map outputs can be combined into a single output. The combiner phase increases speed in the Shuffling phase by improving the performance of Jobs.
The following diagram shows how all the four phases of MapReduce have been applied.

Hadoop YARN
The concept of Hadoop YARN is to split up the functionalities of resource management and job scheduling/monitoring into separate daemons. The idea is to have a global ResourceManager (RM) and per-application ApplicationMaster (AM). An application is either a single job or a DAG of jobs.
The ResourceManager and the NodeManager form the data-computation framework. The ResourceManager is the ultimate authority that arbitrates resources among all the applications in the system. The NodeManager is the per-machine framework agent who is responsible for containers, monitoring their resource usage (CPU, memory, disk, network), and reporting the same to the ResourceManager/Scheduler. The per-application ApplicationMaster is, in effect, a framework-specific library and is tasked with negotiating resources from the ResourceManager and working with the NodeManager(s) to execute and monitor the tasks.
In the Architecture below shows that working of Resource Manager & Node Manager,

c. Running Spark Applications on YARN
A Spark application is the highest-level unit of computation in Spark. A Spark application can be used for a single batch job, an interactive session with multiple jobs, or a long-lived server continually satisfying requests. A Spark job can consist of more than just a single map and reduce. On the other hand, a YARN application is the unit of scheduling and resource allocation. There is a one-to-one mapping between these two terms in case of a Spark workload on YARN; i.e, a Spark application submitted to YARN translates into a YARN application.
YARN controls resource management, scheduling, and security when we run spark applications on it. It is possible to run an application in any mode here, whether it is cluster mode or client mode.
Spark Driver
The Spark driver is universal across Spark deployments irrespective of the cluster manager used.

Spark applications are coordinated by the SparkContext (or SparkSession) object in the main program, which is called the Driver. In plain words, the code initializing SparkContext is your driver. The driver process manages the job flow and schedules tasks and is available the entire time the application is running (i.e, the driver program must listen for and accept incoming connections from its executors throughout its lifetime. As such, the driver program must be network addressable from the worker nodes).
Spark Modes of Deployment — Cluster mode and Client Mode
While we talk about deployment modes of spark, it specifies where the driver program will be run, basically, it is possible in two ways. At first, either on the worker node inside the cluster, which is also known as Spark cluster mode. Secondly, on an external client, what we call a client spark mode.
When for execution, we submit a spark job to local or on a cluster, the behavior of spark job totally depends on one parameter, that is the “Driver” component. Where the “Driver” component of the spark job will reside, it defines the behavior of the spark job.
Each application instance has an ApplicationMaster process, in YARN. That is generally the first container started for that application. However, the application is responsible for requesting resources from the ResourceManager. As soon as resources are allocated, the application instructs NodeManagers to start containers on its behalf. For an active client, ApplicationMasters eliminate the need. Basically, the process of starting the application can terminate. Also, the coordination continues from a process managed by YARN running on the cluster.
Spark Client Mode
The” driver” component of the spark job will run on the machine from which the job is submitted. Hence, this spark mode is basically “client mode”.
In the client mode, we have Spark installed in our local client machine, so the Driver program (which is the entry point to a Spark program) resides in the client machine i.e. we will have the SparkSession or SparkContext in the client machine.
Whenever we place any request like “spark-submit” to submit any job, the request goes to the Resource Manager then the Resource Manager opens up the Application Master in any of the Worker nodes.
The below figure shows the Resource Manager & Node Manager communication in the client mode,
While we run spark on YARN, Spark executor runs as a YARN container. There is a case where MapReduce schedules a container and starts a JVM for each task. There spark hosts multiple tasks within the same container. Hence, it enables several orders of magnitude faster task startup time.
To request executor containers from YARN, the ApplicationMaster is merely present here. To schedule works the client communicates with those containers after they start.
The below figure shows the communication between Client Application, Resource Manager, Node Manager & Spark job in the client mode,
Spark Cluster Mode
Similarly, here “driver” component of the spark job will not run on the local machine from which the job is submitted. Hence, this spark mode is basically “cluster mode”. In addition, here spark job will launch the “driver” component inside the cluster.
The only difference in this mode is that Spark is installed in the cluster, not in the local machine. Whenever we place any request like “spark-submit” to submit any job, the request goes to the Resource Manager then the Resource Manager opens up the Application Master in any of the Worker nodes.
Now, the Application Master will launch the Driver Program (which will be having the SparkSession/SparkContext) in the Worker node.
That means, in cluster mode the Spark driver runs inside an application master process which is managed by YARN on the cluster, and the client can go away after initiating the application. Whereas in client mode, the driver runs in the client machine, and the application master is only used for requesting resources from YARN.
The below figure shows the communication between Client Application, Resource Manager, Node Manager & Spark job in the cluster mode,
When the driver runs in the application master on a cluster host, which YARN chooses, that spark mode is a cluster mode. It signifies that the process, which runs in a YARN container, is responsible for various steps. Such as driving the application and requesting resources from YARN.
The below figure shows the communication between Cluster Application, Resource Manager, Node Manager & Spark job in the Cluster mode,
Note: For using spark interactively, cluster mode is not appropriate. Since applications that require user input need the Spark driver to run inside the client process, for example, spark-shell and pyspark. That initiates the spark application.
Executor and Container
Each Spark executor runs as a YARN container. Spark executors for an application are fixed, and so are the resources allotted to each executor, a Spark application takes up resources for its entire duration. This is in contrast with a MapReduce application which constantly returns resources at the end of each task, and is again allotted at the start of the next task. Also, since each Spark executor runs in a YARN container, YARN & Spark configurations have a slight interference effect.
Configuration and Resource Tuning
To get Spark running on YARN we will be addressing only a few important configurations (both Spark and YARN), and the relations between them. We will first focus on some YARN configurations, and understand their implications, independent of Spark.
i. yarn.nodemanager.resource.memory-mb: It is the amount of physical memory, in MB, that can be allocated for containers in a node. This value has to be lower than the memory available on the node.
<name>yarn.nodemanager.resource.memory-mb</name> <value>16384</value> <!-- 16 GB -->
ii. yarn.scheduler.minimum-allocation-mb: It is the minimum allocation for every container request at the ResourceManager, in MBs. In other words, the ResourceManager can allocate containers only in increments of this value.
<name>yarn.scheduler.minimum-allocation-mb</name> <value>2048</value><!-- 2 GB -->
iii. yarn.scheduler.maximum-allocation-mb: The maximum allocation for every container request at the ResourceManager, in MBs.
<name>yarn.scheduler.maximum-allocation-mb</name> <value>8192</value><!-- 8 GB -->
We will refer to the above statement in further discussions as the Boxed Memory Axiom (just a fancy name to ease the discussions). A similar axiom can be stated for cores as well, although we will not venture forth with it in this article.
Let us now move on to certain Spark configurations. In particular, we will look at these configurations from the viewpoint of running a Spark job within YARN.
iv. spark.executor.memory: . In essence, the memory request is equal to the sum of spark.executor.memory + spark.executor.memoryOverhead. Thus, it is this value which is bound by our axiom.
v. spark.driver.memory: In cluster deployment mode, since the driver runs in the ApplicationMaster which in turn is managed by YARN, this property decides the memory available to the ApplicationMaster, and it is bound by the Boxed Memory Axiom. But as in the case of spark.executor.memory, the actual value which is bound is spark.driver.memory + spark.driver.memoryOverhead. In the case of client deployment mode, the driver memory is independent of YARN and the axiom is not applicable to it. In turn, it is the value spark.yarn.am.memory + spark.yarn.am.memoryOverhead which is bound by the Boxed Memory Axiom.
For more detail about Apache Spark you can read my another blog:
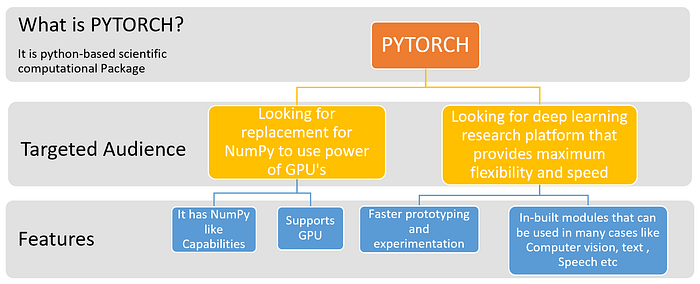
PyTorch
PyTorch is Deep learning frameworks have often focused on either usability or speed, but not both. PyTorch is a machine learning library that shows that these two goals are in fact compatible: it provides an imperative and Pythonic programming style that supports code as a model, makes debugging easy, and is consistent with other popular scientific computing libraries, while remaining efficient and supporting hardware accelerators such as GPUs.
PyTorch is a Python-based scientific computing package serving two broad purposes:
i. A replacement for NumPy to use the power of GPUs and other accelerators.
ii. An automatic differentiation library that is useful to implement neural networks.
This library has three levels of abstraction:
i. Tensor − Imperative n-dimensional array which runs on GPU.
ii. Variable − Node in the computational graph. This stores data and gradient.
iii. Module − Neural network layer which will store state or learnable weights.

PyTorch extends the Python multiprocessing module into torch.multiprocessing, which is a drop-in replacement for the built-in package and automatically moves the data of tensors sent to other processes to shared memory instead of sending it over the communication channel.
PyTorch organizes values into Tensors which are generic n-dimensional arrays with a rich set of data manipulating operations. A Module defines a transform from input values to output values, and its behavior during the forward pass is specified by its forward member function. A Module can contain Tensors as parameters.
For example, a Linear Module contains a weight parameter and a bias parameter, whose forward function generates the output by multiplying the input with the weight and adding the bias. An application composes its own Module by stitching together native Modules (e.g., linear, convolution, etc.) and Functions (e.g., relu, pool, etc.) in the custom forward function. A typical training iteration contains a forward pass to generate losses using inputs and labels, a backward pass to compute gradients for parameters, and an optimizer step to update parameters using gradients. More specifically, during the forward pass, PyTorch builds an autograd graph to record actions performed. Then, in the backward pass, it uses the autograd graph to conduct backpropagation to generate gradients. Finally, the optimizer applies the gradients to update parameters. The training process repeats these three steps until the model converges.
For more detail about PyTorch you can read my another blog:
SparkTorch
This is an implementation of Pytorch on Apache Spark. The goal of this library is to provide a simple, understandable interface in distributing the training of your Pytorch model on Spark. With SparkTorch, you can easily integrate your deep learning model with an ML Spark Pipeline. Underneath the hood, SparkTorch offers two distributed training approaches through tree reductions and a parameter server. Through the API, the user can specify the style of training, whether that is distributed synchronous or hogwild.
Like SparkFlow, SparkTorch’s main objective is to seamlessly work with Spark’s ML Pipelines. This library provides three core components:
i. Data parallel distributed training for large datasets. SparkTorch offers distributed synchronous and asynchronous training methodologies. This is useful for training very large datasets that do not fit into a single machine.
ii. Full integration with Spark’s ML library. This ensures that you can save and load pipelines with your trained model.
iii. Inference. With SparkTorch, you can load your existing trained model and run inference on billions of records in parallel.
On top of these features, SparkTorch can utilize barrier execution, ensuring that all executors run concurrently during training (This is required for synchronous training approaches).
B. Step-by-Step Distributed training of MNIST data using SparkTorch
Step 01: Firstly, we will set Spark & Python Environment.
## Set Python - Spark environment.
import os
import sys
#Setting the path for Spark
# os.environ['SPARK_HOME'] = "/home/Kunal/Downloads/spark-2.4.7-bin-hadoop2.7"
os.environ['PYSPARK_SUBMIT_ARGS'] = '--packages \ org.apache.spark:spark-sql-kafka-0-10_2.11:2.4.7,org.apache.spark:spark-streaming-kafka-0-10_2.11:2.4.7 \ pyspark-shell'
os.environ['PYSPARK_PYTHON'] = sys.executable
os.environ['PYSPARK_DRIVER_PYTHON'] = sys.executableStep 02: In this step , we will import all relevent packages like SparkTorch, pytorch, pyspark. Here SparkTorch requires Apache Spark >= 2.4.4, and has only been tested on PyTorch versions >= 1.3.0. & SparkML is used for provide a uniform set of high-level APIs that help users create and tune practical machine learning pipelines, SparkContext is the entry gate of Apache Spark functionality and SparkSession introduced in version Spark 2.0, It is an entry point to underlying Spark functionality in order to programmatically create Spark RDD, DataFrame and DataSet. SparkSession’s object spark is default available in spark-shell and it can be created programmatically using SparkSession builder pattern.
#import packages
from pyspark.ml.feature import VectorAssembler
from pyspark.sql import SparkSession
from pyspark.ml.pipeline import Pipeline
from pyspark.ml.evaluation import MulticlassClassificationEvaluator from sparktorch import serialize_torch_obj, SparkTorch
import torch
import torch.nn as nn
from sparktorch import SparkTorch, serialize_torch_obj_lazy
from pyspark.sql.functions import rand
## Create SparkContext, SparkSession
from pyspark.sql import *
import pyspark
from pyspark.conf import SparkConf
from pyspark import SparkContext
from pyspark.sql import SparkSession
from pyspark.sql.types import *
from pyspark.sql.functions import col, udf, columnStep 03: In this step, we will define Spark configuration on YARN in Client mode, and also we have created SparkSession with enable hive support. In the client mode, we have Spark installed in our local client machine, so the Driver program (which is the entry point to a Spark program) resides in the client machine i.e. we will have the SparkSession or SparkContext in the client machine. In case of hive support Spark knows two catalogs, hive and in-memory. If you set enableHiveSupport(), then spark.sql.catalogImplementation is set to hive, otherwise to in-memory. So if you enable hive support, spark.catalog.listTables().show() will show you all tables from the hive metastore. But this does not mean hive is used for the query*, it just means that spark communicates with the hive-metastore, the execution engine always sparks. There are actually some functions like percentile und percentile_approx which are native hive UDAF (User-Defined Aggregation Functions (UDAFs) are an excellent way to integrate advanced data-processing into Hive).
If you use enableHiveSupport, then you can:
- write and read to/from Hive persistent metastore
- use Hive’s UDFs
- use Hive’s SerDe
#setting configuration
conf = SparkConf().setAppName("Python_Spark_example").setMaster('yarn-client').set("spark.executor.memory","5g")
sc = SparkContext(conf=conf)
sc.setLogLevel("ERROR")
spark = SparkSession \
.builder \
.appName("Python Spark SQL basic example") \
.config("spark.sql.catalogImplementation=hive").enableHiveSupport() \
.getOrCreate()Step 04: In this step, we will read mnist_train.csv dataset from Hadoop Distributed File System (HDFS) into Spark Dataframe. Though Spark supports to read from/write to files on multiple file systems like Amazon S3, Hadoop HDFS, Azure, GCP e.t.c, the HDFS file system is mostly used at the time of writing this article. If you have your tsv file in HDFS at /home/kunal/data then the following code will read the file into a DataFrame
##Test Example
sqlContext.read.
format("com.databricks.spark.csv").
option("delimiter","\t").
option("header","true").
load("hdfs:///home/kunal/data/tsvtest.tsv").showAlso, like any other file system, we can read and write TEXT, CSV, Avro, Parquet, and JSON files into HDFS. Spark RDD natively supports reading text files and later with DataFrame, Spark added different data sources like CSV, JSON, Avro, and Parquet. Based on the data source you may need a third-party dependency and Spark can read and write all these files from/to HDFS.
#Read csv file from HDFS file system into DataFrame
df = spark.read.option("inferSchema", "true").csv('hdfs://localhost:9000//user/kunal/examples/mnist_train.csv').coalesce(2)Step 05: In this step, we will convert data types into Double types. Column provides cast a method with DataType the instance. In PySpark withColumn(), selectExpr(), and SQL expression to cast the from String to Int (Integer Type), String to Boolean e.t.c. Function DataFrame.filter or DataFrame.where can be used to filter out null values. Function filter is an alias name for where function.
#Typecast features into double
for col_name in df.columns:
df = df.withColumn(col_name, col(col_name).cast('Double'))#Filter
df=df.filter("_c13 is not null")
Step 06: In this step, we will define a Neural Network. PyTorch provides the elegantly designed modules and classes torch.nn , torch.optim , Dataset , and DataLoader to help you create and train neural networks. Here we have taken mnist_train.csv the dataset. In this dataset each row consists of 785 values: the first value is the label (a number from 0 to 9) and the remaining 784 values are the pixel values (a number from 0 to 255). In the defined Neural Network model, we have taken input_size = 784, hidden_sizes = [256, 256] & output_size = 10. The nn.Sequential wraps the layers in the network. There are three linear layers with ReLU activation ( a simple function that allows positive values to pass through, whereas negative values are modified to zero ). The output layer is a linear layer with Softmax activation because this is a classification problem.
PyTorch provides methods to create random or zero-filled tensors, which we will use to create our weights and bias for a simple linear model. These are just regular tensors, with one very special addition: we tell PyTorch that they require a gradient. This causes PyTorch to record all of the operations done on the tensor so that it can calculate the gradient during back-propagation automatically.
#Define Neural Network
network = nn.Sequential(
nn.Linear(784, 256),
nn.ReLU(),
nn.Linear(256, 256),
nn.ReLU(),
nn.Linear(256, 10),
nn.Softmax(dim=1)
)Step 07: In this step, we used to create a Torch object for training, you will need to utilize the serialize_torch_obj from SparkTorch. To do so, simply add your network, loss criterion, the optimizer class, and any options as a dictionary to supply to the optimizer (such as learning rate).
# Build the pytorch object
torch_obj = serialize_torch_obj(
model=network,
criterion=nn.CrossEntropyLoss(),
optimizer=torch.optim.Adam,
lr=0.0001
)Step 08: In this step, we used VectorAssembler having the following signature,
class pyspark.ml.feature.VectorAssembler(inputCols=None, outputCol=None, handleInvalid=’error’):
VectorAssembler is a transformer that combines a given list of columns into a single vector column. It is useful for combining raw features and features generated by different feature transformers into a single feature vector, in order to train ML models like logistic regression and decision trees. VectorAssembler accepts the following input column types: all numeric types, a boolean type, and vector type. In each row, the values of the input columns will be concatenated into a vector in the specified order.
Note: For VectorAssembler, we do not need StringIndexer and OneHotEncoder, if your data have all numeric values.
# Setup features
vector_assembler = VectorAssembler(inputCols=df.columns[1:785], outputCol='features')Step 09: If you just want to get the Pytorch model after training, you can execute the code below. We have the following parameters like verbose Integer 0, 1, or 2. Verbosity mode. Verbose=0 (silent)
Verbose=1 (progress bar)
Train on 186219 samples, validate on 20691 samples
Epoch 1/2
186219/186219 [==============================] - 85s 455us/step - loss: 0.5815 - acc:
0.7728 - val_loss: 0.4917 - val_acc: 0.8029
Train on 186219 samples, validate on 20691 samples
Epoch 2/2
186219/186219 [==============================] - 84s 451us/step - loss: 0.4921 - acc:
0.8071 - val_loss: 0.4617 - val_acc: 0.8168Verbose=2 (one line per epoch)
Train on 186219 samples, validate on 20691 samples
Epoch 1/1
- 88s - loss: 0.5746 - acc: 0.7753 - val_loss: 0.4816 - val_acc: 0.8075
Train on 186219 samples, validate on 20691 samples
Epoch 1/1
- 88s - loss: 0.4880 - acc: 0.8076 - val_loss: 0.5199 - val_acc: 0.8046The EarlyStopping the callback can be used to monitor a validation metric and stop the training when no improvement is observed. Often, the first sign of no further improvement may not be the best time to stop training. This is because the model may coast into a plateau of no improvement or even get slightly worse before getting much better. We can account for this by adding a delay to the trigger in terms of the number of epochs on which we would like to see no improvement. This can be done by setting the “patience” argument.
# Create a SparkTorch Model with torch distributed. Barrier #execution is on by default for this mode.
spark_model = SparkTorch(
inputCol='features',
labelCol='_c0',
predictionCol='predictions',
torchObj=torch_obj,
iters=1000,
verbose=1,
miniBatch=256,
earlyStopPatience=40,
validationPct=0.2
)Step 10: For saving and loading pipelines custom ML Transformers in pure python has not been implemented in PySpark, an extension has been added here to make that possible. save() method to save a Pyspark Pipeline with Apache Spark on the Hadoop HDFS file system.
Spark also consists of a function called saveAsTextFile(), which saves the path of a file and writes the content of the RDD to that file. The path is considered a directory, and multiple outputs will be produced in that directory. This is how Spark becomes able to write output from multiple codes.
# Can be used in a pipeline and saved.
p = Pipeline(stages=[vector_assembler, spark_model]).fit(df)
#saving otput into HDFS file system
p.save('simple_dnn')Step 11: We can perform prediction & evaluation by using the following methods, transform(df) returns an array of elements after applying a transformation to each element in the input array. The Spark ML provides Weighted Precision & Weighted Recall metrics only as part of MulticlassClassificationEvaluator() the module. If you’re looking to have an equivalent interpretation of the Overall Precision metric, especially incase of Binary Classification equivalent to Scikit world, then better to compute Confusion Matrix and evaluate using the formula of Precision & Recall.
# Run predictions and evaluation
predictions = p.transform(df).persist()
evaluator = MulticlassClassificationEvaluator(labelCol="_c0", predictionCol="predictions", metricName="accuracy")
accuracy = evaluator.evaluate(predictions)
print("Train accuracy = %g" % accuracy)
##Train accuracy = 0.787133Note:
There are two main training options with SparkTorch: async and hogwild. The async mode utilizes the torch distributed package, ensuring that the networks are in sync through each iteration. This is the most supported version. When using this option, you will need to be aware that barrier execution is enforced, meaning that the parallelism will need to match the partitions. The Hogwild approach utilizes a Flask Service underneath the hood. When using Hogwild, it is strongly recommended that you use the useBarrier option to force barrier execution.
C. Final output results on HDFS file system
In YARN, each application instance has an ApplicationMaster process, which is the first container started for that application. The application is responsible for requesting resources from the ResourceManager. Once the resources are allocated, the application instructs NodeManagers to start containers on its behalf. ApplicationMasters eliminate the need for an active client: the process starting the application can terminate, and coordination continues from a process managed by YARN running on the cluster.
For Monitoring purposes below figure shows that task processing on YARN using Apache Spark. This screenshot for the application comes from the YARN ResourceManager web interface. This is where all the information from the Spark applications can be found.
The datanode data directory which is given for the dfs.datanode.data.dir in hdfs-site.xml is used to store the blocks of the files you store in HDFS, should not be referenced as HDFS directory path. The below figure shows that the final output in the HDFS file system.

You can download the final code the entire notebook is available here on my Github repository.
D. Results & Conclusion
In summary, we built a new environment with PyTorch and Apache Spark, used them to classify handwritten digits from the MNIST train dataset, and hopefully developed a good intuition using PyTorch. We also used YARN with Apache Spark for distributed processing. Finally, we got the training accuracy on mnist_train.csv dataset is 78.7133%. For further information, the official PyTorch documentation is really nicely written and the forums are also quite active!
E. References
i. https://modelzoo.co/model/sparktorch
iii. https://github.com/dmmiller612/sparktorch
iv.https://spark.apache.org/docs/3.1.1/api/python/reference/api/pyspark.ml.feature.VectorAssembler.html
v. https://searchdatamanagement.techtarget.com/definition/Hadoop-Distributed-File-System-HDFS
vi. https://nextjournal.com/gkoehler/pytorch-mnist
vii. http://seba1511.net/dist_blog/
viii. Scaling Distributed Machine Learning with the Parameter Server
ix. Hogwild!: A Lock-Free Approach to Parallelizing Stochastic Gradient Descent
x. An overview of the Hadoop/MapReduce/HBase framework and its current applications in bioinformatics
xi. https://www.geeksforgeeks.org/hadoop-different-modes-of-operation/
xii. High Performance Machine Learning, Deep Learning, and Data Science

{kind=link}